[2026 반도체] 테슬라 2나노 AI6 칩 삼성 파운드리 대량 발주와 엔비디아 루빈이 가리키는 미래

지난 10년 동안 전 세계의 천재들과 억만장자들은 오직 한 곳만 바라보며 달렸습니다. 더 거대한 컴퓨터 창고를 짓고, 더 복잡한 신경망을 만들어서, 세상의 모든 데이터를 집어삼키게 만드는 것. 이른바 '중앙집중형 학습'이라는 거대한 뇌를 키우는 데에만 수백조 원을 쏟아부었죠.
그런데 이제, 그 거대한 뇌가 우리에게 이렇게 속삭이기 시작했습니다. "이제 공부는 끝났어. 이제부터는 현실에서 움직일 시간이야."
오늘 제가 여러분께 들려드릴 이야기는, 화면 속에 갇혀 있던 이 거대한 지능이 어떻게 우리의 노트북으로, 스마트폰으로, 그리고 두 발로 걷는 로봇의 육체 속으로 침투하고 있는지에 대한 숨 막히는 첩보전입니다. 단순히 칩 하나를 더 빠르게 만드는 시시한 이야기가 아닙니다. 구리선을 통째로 뽑아내 빛으로 바꾸고, 머리카락 두께를 반으로 쪼개며, 텍사스 사막 한가운데서 비밀스러운 동맹이 맺어지는 이 거대한 '시스템 수준의 특이점'에 대한 썰을 지금부터 생생하게 풀어드리겠습니다. 팝콘 하나 챙기시고, 편안하게 따라와 주세요.

- 제1막: 내 책상 위로 내려온 천재들, 그리고 병목의 시작
이야기의 시작은 이렇습니다. 클라우드에 떠 있던 똑똑한 지능을 내 방 책상 위의 PC, 즉 '에지 디바이스'로 끌어내리려다 보니 아주 끔찍한 문제가 터졌습니다.
기존 컴퓨터의 뇌인 CPU로 인공지능의 복잡한 행렬 곱셈을 시키려니 너무 멍청할 정도로 비효율적이었고, 그래픽카드인 GPU한테 시키려니 힘은 센데 전기를 너무 퍼먹어서 노트북 배터리가 순식간에 녹아내렸죠.
그래서 인텔, 퀄컴, 애플 같은 거인들은 아주 영리한 묘수를 냅니다. "아, 전기를 아주 조금만 먹으면서 수학 계산만 기가 막히게 잘하는 전용 칩을 아예 박아버리자!" 그렇게 탄생한 게 바로 NPU, 신경망 처리 장치입니다. 이 녀석은 AI 계산을 할 때 CPU보다 무려 10배에서 40배나 효율적이고, 똑같은 일을 시켜도 GPU보다 전기를 44%나 덜 먹는 진짜배기 용병이었습니다.
2026년, 이 NPU를 둘러싼 윈도우 진영(x86, ARM)과 애플 진영의 피 튀기는 살육전이 벌어집니다. 다들 자기가 최고라고 떠들었죠.
퀄컴의 스냅드래곤 X2 엘리트가 꺼내든 무기는 초당 80에서 85조 번을 계산하는 85 TOPS의 압도적인 속도였습니다. 덕분에 이미지를 그려내는 데 단 7.25초밖에 걸리지 않았죠. 반면 AMD의 라이젠 AI 400(스트릭스)은 60 TOPS, 인텔의 코어 울트라 200V(루나레이크)는 48 TOPS로 뒤를 이었습니다. 애플의 최신 M4 Max는 38 TOPS로 숫자만 보면 꼴찌였습니다.
 그런데 여기서 기가 막힌 반전이 일어납니다.
진짜 거대하고 똑똑한 언어 모델(로컬 LLM)을 노트북 안에서 돌리려고 했더니, 계산 속도 1등이던 퀄컴과 인텔이 숨을 헐떡이며 쓰러져버린 겁니다. 반대로 꼴찌인 줄 알았던 애플은 무려 700억 개 파라미터(70B) 규모의 미친 듯이 무거운 모델을, 겨우 60와트짜리 전력만 쓰면서 코웃음 치듯 돌려버렸죠.
그런데 여기서 기가 막힌 반전이 일어납니다.
진짜 거대하고 똑똑한 언어 모델(로컬 LLM)을 노트북 안에서 돌리려고 했더니, 계산 속도 1등이던 퀄컴과 인텔이 숨을 헐떡이며 쓰러져버린 겁니다. 반대로 꼴찌인 줄 알았던 애플은 무려 700억 개 파라미터(70B) 규모의 미친 듯이 무거운 모델을, 겨우 60와트짜리 전력만 쓰면서 코웃음 치듯 돌려버렸죠.
이게 도대체 무슨 조화일까요?
비밀은 바로 '메모리의 크기와 속도'에 있었습니다. 퀄컴과 인텔 진영은 최대 메모리가 32GB에서 48GB 수준이었고, 데이터가 지나가는 통로(대역폭)도 136 GB/s 정도가 한계였습니다. 반면 애플은 무려 128GB라는 거대한 통합 메모리를 노트북 안에 통째로 때려 박고, 통로 넓이도 546 GB/s로 어마어마하게 뚫어놓았던 겁니다.
수학적으로 한번 계산해 볼까요?
노트북에서 특정 인공지능 모델을 돌리려면 메모리 크기를 계산하는 아주 냉혹한 공식이 있습니다. '파라미터 수 × 파라미터당 바이트 수 × 1.2(오버헤드 여유분)' 이 공식을 써야 합니다. 이때 용량을 확 줄여주는 양자화 기술을 쓰게 되는데, 2바이트를 먹는 FP16 포맷 대신, 성능 저하는 3~5%로 막으면서 용량은 72%나 아껴주는 4비트 'Q4_K_M'이라는 마법의 포맷이 가장 인기입니다. 이 녀석은 파라미터당 0.55바이트만 차지하죠.
자, 계산기를 두드려보겠습니다. 700억 개(70B) 모델에 0.55를 곱하고 1.2를 곱하면? 네, 무려 42기가바이트의 여유 메모리가 무조건 필요하다는 결론이 나옵니다. 심지어 대화의 기억력(컨텍스트 윈도우)을 32K로 늘리면 메모리가 32GB나 더 필요해집니다. 그러니 애초에 32GB 메모리를 가진 인텔이나 퀄컴 노트북은 물리적으로 돌리고 싶어도 돌릴 수가 없었던 겁니다. 130억에서 300억 개 파라미터 모델 수준에 갇혀버린 거죠. 결국 지능의 크기는 계산 속도가 아니라, 메모리가 결정한다는 뼈아픈 진실이 드러난 순간입니다.
- 제2막: 뜨거운 책상을 치워라, 메모리 서브시스템의 혁명
뇌가 아무리 똑똑해도 책상이 좁으면 바보가 된다는 걸 깨달은 삼성전자 같은 메모리 회사들은 완전히 칼을 뽑아 들었습니다. 기존에 컴퓨터에 꽂아 쓰던 막대기 모양의 램(DDR DIMM)은 전기도 너무 많이 먹고 속도도 느려 터져서 도저히 쓸 수가 없었거든요.
 그래서 삼성이 내놓은 비장의 카드가 바로 'LPCAMM2'입니다. 이름이 좀 어렵죠? 쉽게 말해 스마트폰에 들어가던 쪼그마한 저전력 메모리(LPDDR5X)들을 납작하게 뭉쳐서 컴퓨터용으로 만든 겁니다.
이 녀석의 파괴력은 상상을 초월합니다. 모듈 하나당 153.6 GB/s라는 미친 대역폭을 뿜어내는데, 기존 서버용 메모리(RDIMM)보다 데이터 처리량이 무려 2.6배나 높습니다. 그런데 더 무서운 건, 전기는 오히려 55%나 덜 먹고 전체 효율은 70%나 끌어올렸다는 겁니다.
그래서 삼성이 내놓은 비장의 카드가 바로 'LPCAMM2'입니다. 이름이 좀 어렵죠? 쉽게 말해 스마트폰에 들어가던 쪼그마한 저전력 메모리(LPDDR5X)들을 납작하게 뭉쳐서 컴퓨터용으로 만든 겁니다.
이 녀석의 파괴력은 상상을 초월합니다. 모듈 하나당 153.6 GB/s라는 미친 대역폭을 뿜어내는데, 기존 서버용 메모리(RDIMM)보다 데이터 처리량이 무려 2.6배나 높습니다. 그런데 더 무서운 건, 전기는 오히려 55%나 덜 먹고 전체 효율은 70%나 끌어올렸다는 겁니다.
전기를 덜 먹는다는 건 열이 안 난다는 뜻이죠. 에어컨 돌리느라 천문학적인 돈을 쏟아붓던 데이터센터 입장에서는 그야말로 구세주가 강림한 겁니다. 얇은 노트북에서도 발열 없이 9,600 MT/s 속도로 최대 96GB까지 지원하니 완벽한 무기가 탄생한 거죠.
여기에 삼성은 아예 24시간 내내 소리 안 나게 주인을 감시해야 하는 온디바이스 기기들을 위해 'LLW(Low Latency Wide) DRAM'이라는 암살자 같은 칩도 준비했습니다. 128 GB/s의 초고속 속도를 내면서도 데이터 하나를 옮길 때 겨우 1.2피코줄(pJ/b)이라는, 먼지 한 톨 수준의 전기밖에 안 먹는 기적의 메모리입니다.
하지만 클라우드에 있는 거대한 데이터센터들은 이걸로도 만족을 못 했습니다. 칩 안에 메모리를 아무리 쑤셔 넣어도 모자랐죠. 그래서 아예 'CXL'이라는 새로운 프로토콜을 도입합니다. 우리가 외장 하드(SSD) 꽂아서 용량 늘리듯이, 컴퓨터 서버 구조를 뜯어고치지 않고도 테라바이트급 메모리를 바깥에서 동적으로 쫙쫙 끌어다 쓰게 만드는 마법의 스위치를 켜버린 겁니다.
- 제3막: 구리선의 죽음, 그리고 빛의 시대
책상을 넓혀놨더니 이제 또 다른 비명이 들려옵니다. 바로 거대한 데이터센터 전체를 뒤덮고 있는 '구리선'들입니다.
옛날에는 칩 안의 트랜지스터만 미세하게 깎으면 만사형통이었죠. 무어의 법칙이라고 부르던 그 시절 말입니다. 그런데 이제는 칩과 칩, 랙과 랙을 연결하는 통신 선이 목을 조르기 시작했습니다. 랙 하나당 120킬로와트 쓰던 전기가 이제 600킬로와트까지 치솟으면서, 구리선으로 전기 신호를 보내려다간 열이 나서 다 타버리고 신호는 중간에 다 끊어져 버리는 끔찍한 사태가 벌어진 겁니다.
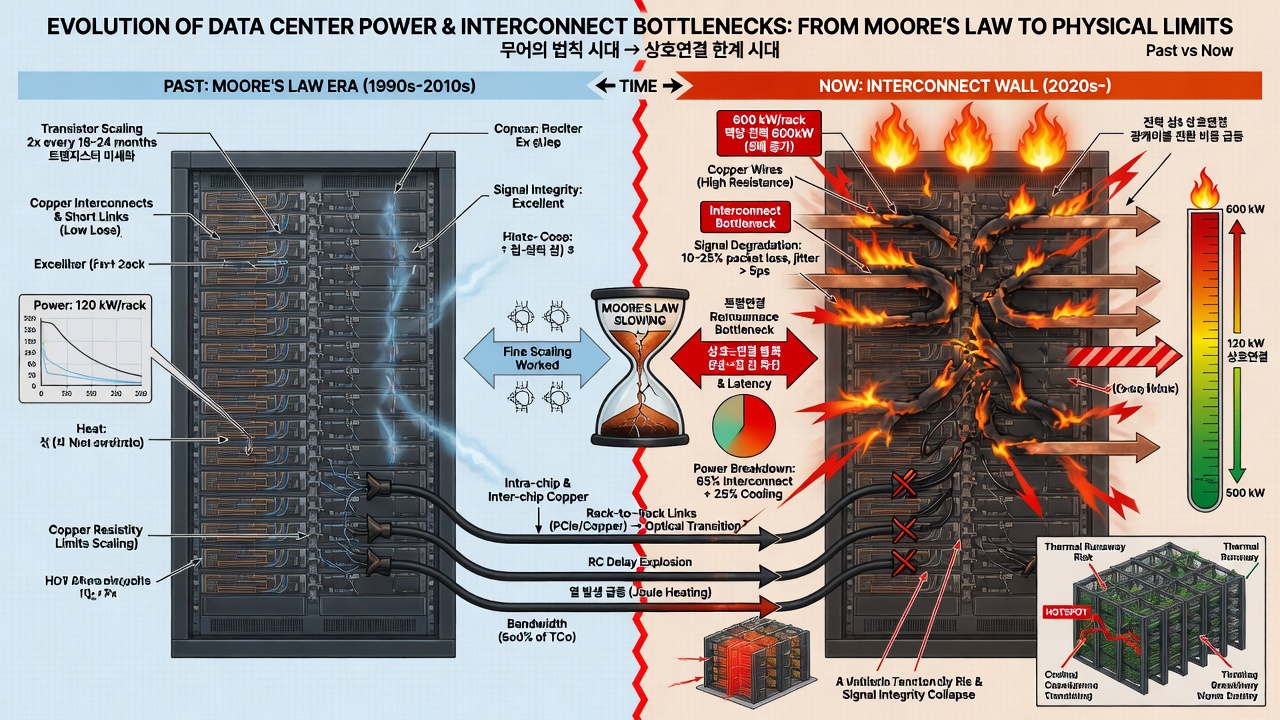 2026년 OFC 컨퍼런스에서 이 문제는 가장 뜨거운 화두였습니다. 데이터센터 자체가 거대한 하나의 컴퓨터가 되어버렸고, 그 혈관을 다시 깔아야 했죠.
2026년 OFC 컨퍼런스에서 이 문제는 가장 뜨거운 화두였습니다. 데이터센터 자체가 거대한 하나의 컴퓨터가 되어버렸고, 그 혈관을 다시 깔아야 했죠.
그래서 업계가 선택한 극약 처방이 바로 'CPO(Co-Packaged Optics)'라는 기술입니다. 쉽게 말해, 구리선으로 전기 신호를 바꿔주는 전력 먹는 하마(SerDes 소자)를 칩에서 아예 뜯어내 버리고, 칩 바로 옆에 빛을 쏘는 부품을 한 패키지로 찰싹 붙여버린 겁니다.
효과는 경이로웠습니다. 엔비디아의 퀀텀-X와 스펙트럼-X 스위치를 보면, 부품 수를 확 줄이면서 전력 효율을 3.5배나 수직 상승시켰고, 고장 날 확률을 줄여 복원력을 10배나 높였습니다. 메타(Meta)는 이미 이 기술로 '9천만 시간 신뢰성 검증'을 끝냈다고 쐐기를 박아버렸죠.
 이 빛의 혁명을 전 세계 표준으로 굳히기 위해, AMD, 브로드컴, 엔비디아, 메타, 마이크로소프트, 오픈AI 6명의 거인들이 모여 'OCI MSA'라는 비밀결사 같은 협정을 맺습니다. 광섬유 하나에 단방향 파장 4개, 양방향 8개를 쏘는 규격을 딱 정해버린 거죠. 브로드컴은 이렇게 말했습니다. "이제 빛으로 통신하는 건 단순히 빠르거나 멀리 가서가 아니다. 구리선보다 '절대적인 전기 소모량' 자체가 훨씬 적기 때문이다." 통신의 패러다임이 완전히 뒤집힌 겁니다.
이 빛의 혁명을 전 세계 표준으로 굳히기 위해, AMD, 브로드컴, 엔비디아, 메타, 마이크로소프트, 오픈AI 6명의 거인들이 모여 'OCI MSA'라는 비밀결사 같은 협정을 맺습니다. 광섬유 하나에 단방향 파장 4개, 양방향 8개를 쏘는 규격을 딱 정해버린 거죠. 브로드컴은 이렇게 말했습니다. "이제 빛으로 통신하는 건 단순히 빠르거나 멀리 가서가 아니다. 구리선보다 '절대적인 전기 소모량' 자체가 훨씬 적기 때문이다." 통신의 패러다임이 완전히 뒤집힌 겁니다.
이 판에서 삼성전자 파운드리가 내놓은 양산 로드맵은 살벌할 정도로 촘촘합니다. 300mm 웨이퍼 위에서, 2027년에는 빛을 다루는 반도체(PIC)와 전기를 제어하는 회로(EIC)를 하나로 합치고, 2028년에는 스위치 칩 바로 옆에 이 녀석들을 찰싹 붙일 계획입니다. 그리고 대망의 2029년에는 아예 GPU와 HBM 메모리가 합쳐진 패키지 안에 빛을 쏘는 부품을 통째로 내장해 버리겠다는 무시무시한 청사진을 그려놓고 있죠.
- 제4막: 궁극의 조립 예술, 어드밴스드 패키징의 지배
그런데 말입니다, 시장 사람들은 HBM 메모리가 부족해서 AI 가속기를 못 만든다고 난리지만, 진짜 무서운 문지기는 따로 숨어있었습니다. 바로 이 모든 칩을 하나로 예쁘게 포장하는 '어드밴스드 패키징' 기술입니다.

지금의 최고급 GPU는 칩 하나 띡 만들어내는 게 아닙니다. 연산하는 GPU와 HBM을 얇은 실리콘 기판 위에 올리고 열과 압력을 가해 미세하게 붙여야 하는 엄청난 예술 작품이죠. TSMC의 'CoWoS'라는 포장 기술이 이 물량을 다 소화하지 못해서, 델이나 슈퍼마이크로 같은 서버 회사들은 무려 50주를 넘게 멍하니 손가락만 빨고 기다려야 하는 상황이 벌어졌습니다.
여기서 등장하는 게 바로 차세대 괴물 메모리, HBM4입니다. 이 녀석은 이전 세대와는 뼈대부터 다릅니다. 데이터가 오가는 통로(인터페이스) 폭을 기존 1,024비트에서 2,048비트로 두 배 찢어버리고, 독립 채널도 16개에서 32개로 늘려서 스택 하나당 초당 2 테라바이트라는 미친 속도를 뿜어냅니다.
하지만 이 괴물을 만들려면 사람의 한계를 시험해야 합니다. 12층, 나아가 16층(HBM4E)으로 메모리를 쌓아 올리면서도 JEDEC이 정해놓은 전체 두께 720 마이크로미터 제한을 지키려면, 메모리 칩 하나를 사람 머리카락 굵기의 절반인 '30 마이크로미터'로 미친 듯이 얇게 깎아내야 하거든요. 게다가 통로가 많아지니 전기를 너무 많이 먹게 되어서, 메모리와 GPU를 이어주는 제일 밑바닥 칩(베이스 다이)을 옛날 공정이 아니라 아예 최첨단 로직 파운드리 공정으로 구워내야 하는 상황에 이르렀습니다. 메모리가 파운드리에 멱살을 잡힌 셈이죠.

바로 여기서 삼성전자 파운드리의 '턴키(Turn-key)' 생태계가 빛을 발합니다. 대만의 TSMC는 포장은 기가 막히게 잘하지만 자기네 메모리가 없습니다. 반면 삼성은 "우리는 첨단 파운드리도 있고, HBM도 우리가 직접 만들고, 포장까지 한 방에 다 해줄 수 있어!"라며 패를 깐 겁니다.
삼성의 포장 기술은 상상을 초월합니다. 옆으로 넓게 붙이는 2.5D 패키징(I-Cube)에서는 실리콘 인터포저를 쓰는 Cube-S, 브릿지를 심는 Cube-E, 가성비 좋은 RDL을 쓰는 Cube-R까지 옵션을 쫙 깔아놨습니다. 더 충격적인 건 위로 쌓아 올리는 3D 패키징(X-Cube)입니다. 기존 범프 결합(Cube-T)을 넘어서서, 차세대 Cube-H 플랫폼에서는 아예 마이크로 범프조차 없애버린 무범프 하이브리드 구리 본딩(HCB)을 써서 간격을 4 마이크로미터 이하로 좁혀버렸습니다. 전기가 새는 걸 원천 차단해 버린 거죠. TSMC의 병목에 지친 빅테크들에게 이보다 완벽한 탈출구는 없었을 겁니다.
- 제5막: 죽은 줄 알았던 왕의 귀환, CPU의 부활
수많은 칩과 빛이 엉켜있는 이 전쟁터에서, 우리는 잠시 잊고 있었던 늙은 왕을 마주하게 됩니다. 바로 CPU입니다.
생성형 AI가 처음 빵 터졌을 때는 다들 행렬 계산에 미쳐있는 GPU만 찬양했습니다. 그런데 지능이 똑똑해지면서 '에이전틱 AI'라는 게 등장합니다. 사용자가 프롬프트 하나를 던지면 인공지능이 혼자서 수천 개의 단계를 쪼개서 검색하고, 판단하고, 소프트웨어를 만지작거리는 시대가 온 겁니다.
 GPU는 단순 계산은 잘하지만, 이런 복잡한 순차적 논리나 조건부 판단(분기 로직) 앞에서는 한없이 바보가 됩니다. 결국 속도가 빠르고 똘똘한 CPU가 나서서 전체 판을 통제해 주지 않으면 시스템이 꼬여버리게 된 거죠.
GPU는 단순 계산은 잘하지만, 이런 복잡한 순차적 논리나 조건부 판단(분기 로직) 앞에서는 한없이 바보가 됩니다. 결국 속도가 빠르고 똘똘한 CPU가 나서서 전체 판을 통제해 주지 않으면 시스템이 꼬여버리게 된 거죠.
엔비디아가 새롭게 발표한 '베라 루빈(Vera Rubin)' 플랫폼을 보면 이 진실이 노골적으로 드러납니다. 그들의 거대한 수냉식 시스템 NVL72를 뜯어보면, 72개의 루빈 GPU와 36개의 베라 CPU가 정확히 2대 1 비율로 짝을 지어 들어가 있습니다. GPU가 계산할 때 CPU가 교통정리를 못해서 생기는 병목을 원천 차단한 겁니다. 여기에 20.7 테라바이트의 HBM4를 달아서 무려 1.6 PB/s의 집적 대역폭을 쏟아내니, 와트당 추론 처리량이 기존 그레이스 블랙웰보다 10배나 껑충 뛰어올랐습니다.
이건 노트북 같은 에지 환경에서도 마찬가지입니다. 엔비디아의 노트북용 슈퍼칩 'RTX 스파크'를 보시죠. 트랜지스터만 700억 개입니다. 이 안에는 20코어짜리 Grace Arm CPU와 Blackwell GPU가 600 GB/s 속도의 NVLink-C2C로 찰싹 붙어있고, 128GB의 통합 LPDDR5X 메모리를 공유합니다. 인텔의 루나레이크나 AMD의 스트릭스 같은 평범한 AI PC에서도, 웹캠 배경을 흐리게 하는 가벼운 일은 NPU에 던져주고 빡센 글쓰기 작업은 GPU로 보내는 이 복잡한 작업 지시를 결국 고성능 CPU가 다 컨트롤하고 있습니다. CPU 없이는 분산형 추론이라는 환상은 그저 모래성에 불과한 겁니다.
- 제6막: 모니터를 찢고 나온 지능, 물리적 AI와 한국 상륙작전
자, 이제 이야기의 가장 소름 돋는 클라이맥스입니다. 화면 속에서 글이나 쓰고 그림을 그리던 지능이, 드디어 물리적인 육체를 얻어 현실 세계로 튀어나오기 시작했습니다.
 엔비디아의 젠슨 황은 분명히 선언했습니다. "다음 성장의 심장은 무조건 '물리적 AI'다."
단어를 예측하는 게 아니라 고전 물리학의 법칙을 따르고, 공간을 추론하며, 카메라와 센서의 데이터를 실시간으로 소화해 로봇의 관절을 움직여야 하는 완전히 새로운 세계입니다.
엔비디아의 젠슨 황은 분명히 선언했습니다. "다음 성장의 심장은 무조건 '물리적 AI'다."
단어를 예측하는 게 아니라 고전 물리학의 법칙을 따르고, 공간을 추론하며, 카메라와 센서의 데이터를 실시간으로 소화해 로봇의 관절을 움직여야 하는 완전히 새로운 세계입니다.
하지만 로봇을 현실에서 훈련시키려면 수십 년이 걸리겠죠. 그래서 엔비디아는 '코스모스(Cosmos)'라는 마법의 매트릭스 환경을 창조해 냅니다. 현실의 중력과 마찰력이 똑같이 적용된 가상 세계 안에서, 로봇들이 수십억 번의 강화 학습을 돌리며 가짜 데이터(합성 학습 데이터)로 스스로 진화하는 미친 생태계를 만들어버린 겁니다.
 그리고 2026년 중순, 이 물리적 AI의 전진 기지를 세우기 위해 젠슨 황이 직접 대한민국에 상륙합니다.
그는 한국의 빵빵한 제조업과 하드웨어 공급망이 아니면 로봇 혁명은 불가능하다는 걸 뼛속까지 알고 있었죠. 입국하자마자 서울 홍대의 한 식당에서 SK 최태원, LG 구광모, 네이버 이해진 등 한국 재계 총수들을 불러모아 삼겹살을 구워 먹으며 로보틱스와 HBM 공급망 작전을 짰습니다.
그리고 2026년 중순, 이 물리적 AI의 전진 기지를 세우기 위해 젠슨 황이 직접 대한민국에 상륙합니다.
그는 한국의 빵빵한 제조업과 하드웨어 공급망이 아니면 로봇 혁명은 불가능하다는 걸 뼛속까지 알고 있었죠. 입국하자마자 서울 홍대의 한 식당에서 SK 최태원, LG 구광모, 네이버 이해진 등 한국 재계 총수들을 불러모아 삼겹살을 구워 먹으며 로보틱스와 HBM 공급망 작전을 짰습니다.
결과는 파격적이었습니다. 현대자동차그룹과 손잡고 30억 달러를 투자해 5만 개의 최첨단 Blackwell GPU가 돌아가는 거대한 AI 팩토리를 한국에 지어버리기로 한 겁니다. 여기서 자율주행과 산업용 로봇의 두뇌가 훈련될 겁니다. 현대와 LG의 공장 인프라에는 젯슨 토어 로보틱스 프로세서가 꽂히고, 심지어 e스포츠 황제 T1의 페이커 이상혁 선수를 찾아가 RTX 스파크가 달린 노트북을 선물하는 쇼맨십까지 보여줬죠. 서울 한복판에 물리적 AI와 로보틱스 R&D 센터를 세워 대규모 채용을 시작한 건, 반도체 설계부터 로봇의 관절(액추에이터), 그리고 공장 자동화까지 완벽한 고리를 한국에서 완성하겠다는 무서운 선전포고였습니다.
- 테슬라의 변심, 그리고 텍사스 사막의 비밀 동맹
이 모든 거대한 판을 뒤흔들 마지막 반전의 주인공은, 일론 머스크의 테슬라입니다.
디지털에서 물리적 세상으로 넘어가는 이 극적인 순간을 테슬라만큼 적나라하게 보여주는 곳은 없습니다.

2026년 초, 테슬라는 그토록 고대하던 차세대 슈퍼 칩 'AI5(기존 HW5)'의 설계를 끝내고 TSMC와 삼성전자에서 양산할 준비(테이프아웃)를 마쳤다고 공식 선언합니다. 사람들은 열광했죠. "드디어 테슬라 자동차에 엄청난 칩이 들어가서 완전 자율주행이 완성되겠구나!"
그런데 일론 머스크가 갑자기 뒤통수를 칩니다. "AI5 칩? 그거 우리 자동차에 안 넣을 건데?"
머스크의 속내는 이랬습니다. 이미 굴러다니는 자동차에 들어있는 기존의 'AI4' 하드웨어만으로도 인간보다 운전을 훨씬 안전하게 잘할 수 있다는 확신이 섰던 겁니다. 테슬라는 부동소수점 대신 정수 처리 아키텍처에 미친 듯이 최적화해서, 고작 200~250W의 제한된 전기만 가지고도 목숨이 걸린 자율주행을 완벽하게 소화해 냈습니다.
실제로 네덜란드, 에스토니아 같은 유럽 국가에서 FSD v14.3.3 버전이 승인받고 실도로를 달리기 시작하면서 AI4의 성능은 이미 증명 끝이었습니다. 충분히 잘 굴러가는 차에 굳이 비싼 하드웨어를 교체(레트로핏)해 주면서 돈을 낭비할 필요가 없다는, 뼛속까지 엔지니어다운 판단이었죠.
 그럼 그 무시무시한 AI5 칩과 다음 세대인 AI6, AI7(Dojo 3)은 다 어디로 갈까요?
정답은 바로 다관절 휴머노이드 로봇 '옵티머스'와 거대한 슈퍼컴퓨터 '도조'였습니다. 차를 똑똑하게 만드는 수준을 넘어서서, 다중 모달 데이터가 오가는 물리적 로봇의 두뇌와 자신들만의 독자적인 거대 인프라를 구축하는 데 모든 화력을 집중하겠다는 뜻이었습니다.
그럼 그 무시무시한 AI5 칩과 다음 세대인 AI6, AI7(Dojo 3)은 다 어디로 갈까요?
정답은 바로 다관절 휴머노이드 로봇 '옵티머스'와 거대한 슈퍼컴퓨터 '도조'였습니다. 차를 똑똑하게 만드는 수준을 넘어서서, 다중 모달 데이터가 오가는 물리적 로봇의 두뇌와 자신들만의 독자적인 거대 인프라를 구축하는 데 모든 화력을 집중하겠다는 뜻이었습니다.
그리고 이 전략적 변심은 반도체 판도에 지각변동을 일으켰습니다.
테슬라 수뇌부는 2026년 초 삼성전자 파운드리를 찾아가 아주 은밀하고 거대한 요구를 합니다. 2나노 공정 기반의 AI6 칩 발주량을 당초 월 1만 6천 장에서 무려 월 4만 장으로 두 배 넘게 폭증시켜 달라고 한 겁니다.
 왜 하필 삼성전자의 미국 텍사스 테일러 공장일까요? 세 가지 이유가 있습니다.
왜 하필 삼성전자의 미국 텍사스 테일러 공장일까요? 세 가지 이유가 있습니다.
첫째, AI6 칩이 자동차용을 넘어 로봇 옵티머스 대량 양산과 도조 슈퍼컴퓨터를 완벽히 대체하는 범용 프로세서로 신분이 격상되었기 때문입니다.
둘째, 테슬라가 2026년 한 해 동안 평소의 2배인 200억 달러를 AI 인프라에 때려 박기로 하면서 무지막지한 칩 물량이 필요해졌습니다.
마지막 셋째, 가장 중요한 '지정학적 리스크'입니다. 미중 갈등과 대만 전쟁 위기가 고조되면서 테슬라는 선언합니다. "No China, No Taiwan!" 중국과 대만에 의존하다간 자칫 회사의 숨통이 끊어질 수 있다는 공포가 작용한 거죠.
물론 테슬라는 보험용으로 TSMC와도 'AI6.5' 개발을 진행 중이긴 합니다. 하지만 삼성이 미국 텍사스 본토에서 파운드리 칩 생산, HBM 메모리 수급, 그리고 어드밴스드 패키징까지 한 방에 해결해 주는 이 '턴키 생태계'의 유혹을 뿌리칠 수는 없었던 겁니다. 테슬라만의 독립적인 '소버린 AI' 제국을 텍사스 사막 한가운데서 완성하겠다는 거대한 야망의 퍼즐이 맞춰진 순간입니다.
 8. 이야기의 끝은 이렇습니다.
8. 이야기의 끝은 이렇습니다.
글로벌 반도체와 인공지능 산업은 지금 되돌아갈 수 없는 특이점을 관통하고 있습니다. 클라우드에 갇혀 무식하게 몸집만 키우던 1세대 인공지능의 시대는 완전히 끝났습니다.
이제 승패를 가르는 룰은 하나입니다. 누가 더 전기를 적게 쓰면서 로컬에서 128GB의 한계를 뛰어넘는 메모리(LPCAMM2, LLW)를 달아줄 것인가. 녹아내리는 구리선 대신 누가 먼저 빛(CPO, OCI)으로 데이터의 고속도로를 깔 것인가. 그리고 30 마이크로미터로 깎아낸 HBM4와 GPU를 3D 무범프 기술로 완벽하게 포장(어드밴스드 패키징)해 낼 것인가.
CPU의 지휘 아래 움직이는 베라 루빈, 삼겹살을 굽던 젠슨 황의 물리적 AI 로보틱스, 그리고 대만과 중국을 버리고 텍사스에서 삼성과 손잡은 테슬라의 옵티머스까지. 이 모든 거대한 움직임은 단 하나의 진실을 향해 달려가고 있습니다.
차세대 컴퓨팅의 왕좌는 그저 트랜지스터 하나를 제일 얇게 잘 깎아내는 자의 것이 아닙니다. 로직 칩, 메모리, 빛으로 통신하는 네트워크, 첨단 포장 기술, 그리고 그것을 담아낼 로봇의 육체까지. 이 모든 것을 가장 유기적으로 연결해 내는 시스템 최적화의 마법사, 그 '턴키 생태계'를 움켜쥔 자만이 내일의 지배자가 될 것입니다.